Written by thread-threads
State Threads是一个C的网络程序开发库,提供了编写高性能、高并发、高可读性的网络程序的开发库,支持UNIX-like平台。它结合了多线程编写并行成的 简单性,一个进程支持多个并发,支持基于事件的状态机架构的高性能和高并发能力。
(译注:提供了EDSM的高性能、高并发、稳定性,“多线程”形式的简单编程方式,用setjmp和longjmp实现的一个线程模拟多线程,即用户空间的多线程,类似于现在的协程和纤程)
Definitions
Internet Applications
网络程序(Internet Application)(IA)是一个网络的客户端或者服务器程序,它接受客户端连接,同时可能需要连接到其他服务器。在IA中,数据的到达 和发送完毕经常操纵控制流,就是说IA是数据驱动的程序。对每个连接,IA做一些有限的工作,包括和peer的数据交换,peer可能是客户端或服务器。IA典型 的事务步骤是:接受连接,读取请求,做一些有限的工作处理请求,将相应写入peer。一个iA的例子是Web服务器,更典型的例子是代理服务器,因为它接受客 户端连接,同时也连接到其他服务器。
我们假定IA的性能由CPU决定,而不是由网络带宽或磁盘IO决定,即CPU是系统瓶颈。
Performance and Scalability
IA的性能一般可以用吞吐量来评估,即每秒的事务数,或每秒的字节数(两者可以相互转换,给定事务的平均大小就可以)。有很多种工具可以用来测量Web程序 的特定负载,譬如SPECweb96, WebStone, WebBench。尽管对扩展性没有通用的定义,一般而言,可扩展性指系统在外部条件改变时维持它的性能的能力。 对于IAs而言,外部条件指连接数(并发),或者底层硬件(CPU数目,内存等)。因此,有两种系统的扩展性:负载能力和系统能力。
(译注:scalability可扩展性,指条件改变了系统是否还能高效运行,譬如负载能力指并发(条件)增多时系统是否能承担这么多负载,系统能力指CPU等增 多时是否能高效的利用多CPU达到更强的能力)
下图描述了客户端数目增多时系统的吞吐量的变化,蓝色线条表示理想状况。最开始时吞吐量程线性增长,这个区间系统和CPU较为空闲。继续增长的连接数导致 系统开始饱和,吞吐量开始触及天花板(CPU跑满能跑到的吞吐量),在天花板之后吞吐量变为平行线不再增长,因为CPU能力到达了极限。在实际应用中,每个 连接消耗了计算资源和内存资源,就算是空闲状态,这些负担都随连接数而增长,因此,实际的IA吞吐量在某个点之后开始往下落(蓝色虚线表示)。开始掉的点, 不是其他的原因,而是由系统架构决定的。
我们将系统有好的负载能力,是指系统在高��负载时仍能很好的工作。SPECweb99基准测试能较好的反应系统的负载能力,因为它测量的是连接在最小流量需求时 系统能支持的最大连接数(译注:如图中Capacity所指出的点即灰色斜线和蓝色线交叉的点)。而不像SPECweb96或其他的基准测试,是以系统的吞吐量来衡量的 (译注:图中Max throughout,即蓝色线的天花板)。
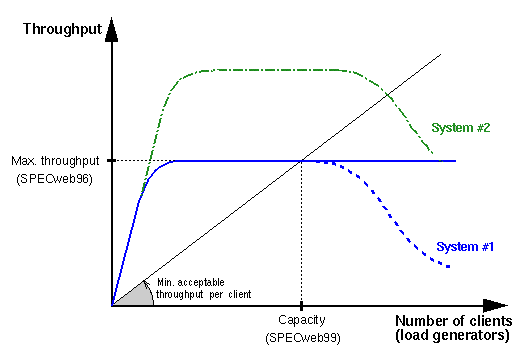
系统能力指程序在增加硬件单元例如加CPU时系统的性能,换句话说,好的系统能力意味着CPU加倍时吞吐量会加倍(图中绿色虚线)。我们假设底层操作系统也 具有很好的系统能力。好的系统能力指假设程序在一个小的机器上运行很好,当有需要换到大型服务器上运行时也能获得很高的性能。就是说,改变服务器环境时, 系统不需要重写或者费很大的劲。
译注: 纵坐标是吞吐量,横坐标是连接数。 灰色的线(min acceptable throughout pre client)表示是客户端的需要的吞吐量,至少这个量才流畅。 蓝色表示理想状态的server,系统能力一直没有问题,能达到最大吞吐量,CPU跑满能跑到的吞吐量。 蓝色虚线表示实际的server,每个连接都会消耗CPU和内存,所以在某个临界点之后吞吐量开始往下掉,这个临界点就是系统结构决定的。好的系统架构能将临界点往后推,稳定的支持更高的并发;差的架构在并发增加时可能系统就僵死了。 灰色虚线表示两个测量基准,一个是SPECweb96测量的是系统最大吞吐量,一个是SPECweb99测量每个连接在最小要求流量下系统能达到的最大连接数,后者更能反应系统的负载能力,因为它测量不同的连接的状况下系统的负载能力。 负载能力指的是系统支撑的最大负载,图中的横坐标上的值,对应的蓝色线和灰色线交叉的点,或者是蓝色线往下掉的点。 系统能力指的是增加服务器能力,如加CPU时,系统的吞吐量是否也会增加,图中绿色线表示。好的系统能力会在CPU增加时性能更高,差的系统能力增加CPU也不会更强。
尽管性能和扩展性对服务器来讲更重要,客户端也必须考虑这个问题,例如性能测试工具。
Concurrency
并发反应了系统的并行能力,分为虚拟并发和物理并发:
虚拟并发是指操作系统同时支持很多并发的连接。
物理并发是指硬件设备,例如CPU,网卡,硬盘等,允许系统并行执行任务。
IA必须提供虚拟并发来支持用户的并发访问,为了达到最大的性能,IA创建的由内核调度的编程实体数目基本上和物理并发的数量要保持一致(在一个数量级上) (译注:有多少个CPU就用多少个进程)。内核调度的编程实体即内核执行对象(kernel execution vehicles),包括Solaris轻量级进程,IRIX内核线程。 换句话说,内核执行对象应该由物理条件决定,而不是由并发决定(译注:即进程数目应该由CPU决定,而不是由连接数决定)。
Existing Architectures
IAs(Internet Applications)有一些常见的被广泛使用的架构,包括基于进程的架构(Multi-Process),基于线程的架构(Multi-Threaded), 和事件驱动的状态机架构(Event-Driven State Machine)。
Multi-Process Architecture
译注:Multi-Process字面意思是多进程,但事件驱动的状态机EDSM也常用多进程,所以为了区分,使用“基于进程的架构”,意为每个连接一个进程的架构。
在基于进程的架构(MP)中,一个独立的进程用来服务一个连接。一个进程从初始化到服务�这个连接,直到服务完毕才服务其他连接。
用户Session是完全独立的,因此,在这些处理不同的连接的进程之间,完全没有同步的必要。因为每个进程有自己独立的地址空间,这种架构非常强壮。 若服务某个连接的进程崩溃,其他的连接不会受到任何影响。然而,为了服务很多并发的连接,必须创建相等数量的进程。因为进程是内核对象,实际上是最“重” 的一种对象,所以至少需要再内核创建和连接数相等的进程。在大多数的系统中,当创建了上千个进程时,系统性能将大幅降低,因为超负荷的上下文切换。 也就是说,MP架构负载能力很弱,无法支持高负载(高并发)。
另一方面,MP架构有很高的系统能力(利用系统资源,稳定性,复杂度),因为不同的进程之间没有共享资源,因而没有同步的负担。
ApacheWeb服务器就是采用的MP架构。
Multi-Threaded Architecture
译注:Multi-Threaded字面意思是多线程,但侧重一个线程服务一个连接的方式,用“基于线程”会更准确
在基于线程(MT)架构中,使用多个独立的线程,它们共享地址空间。和MP结构的进程一样,每个线程独立服务每个连接直到服务完毕,这个线程才用来服务其他 连接。
很多现代的UNIX操作系统实现了一个多对一的模型,用来映射用户空间的线程到系统内核对象。在这个模型中,任意多数量的用户空间线程复用少量的内核执行 对象,内核执行对象即为虚拟处理器。当用户空间线程调用了一个阻塞的系统调用时,内核执行对象也会在内核阻塞。如果没有其他没有阻塞的内核执行对象, 或者有其他需要运行的用户空间线程,一个新的内核执行对象会被自动创建,这样就防止一个线程阻塞时其��他线程都被阻塞。
由于IAs由网络IO驱动,所有的并发连接都会阻塞在不同的地方。因此,内核执行对象的数目会接近用户空间线程的数目,也就是连接的数目。此时,多对一的 模型就退化为一对一的模型,和MP架构一样,内核执行对象的数目由并发决定而不是由CPU数目决定。和MP一样,这降低了系统的负载能力。尽管这样,由于内核 线程是轻量级进程,使用了较少的资源,比内核进程要轻,MT架构比MP架构在负载能力方面稍强一些。
在MT架构中,内核线程共享了地址空间,各种同步锁破坏了系统能力。尽管程序可以很小心的避免锁来提高程序性能(是个复杂的任务),标准库函数和系统调用 也会对通用资源上锁,例如,平台提供的线程安全函数,例如内存分配函数(malloc,free等)都是用了一个全局锁。另外一个例子是进程的文件描述表,这个 表被内核线程共享,在系统调用(open,close等)时需要保护。除此之外,多核系统中需要在CPU之间维护缓存的一致,当不同的线程运行在不同的CPU上并修 改同样的数据时,严重降低了系统的性能。
为了提高负载能力,产生了一些不同类型的MT架构:创建多组线程,每组线程服务一个任务,而不是一个线程服务一个连接。例如,一小组线程负责处理客户端连接 的任务,另外一组负责处理请求,其他的负责处理响应。这种架构的主要优点是它对并发和线程解耦了,不再需要同等数量的线程服务连接。尽管这样,线程组之间 必须共享任务队列,任务队列需要用锁来保护(典型的生产者-消费者问题)。额外的线程同步负担导致在多处理器系统上性能很低。也就是说,这种架构用系统能 力换取了负载能力(用性能换高并发)。
当然,线程编程的噩梦,包括数据破坏,死锁,条件竞争,也导致了任何形式的MT架构无法实用。
Event-Driven State Machine Architecture
在基于事件驱动的状态机架构(EDSM)中,一个进程用来处理多个并发。Comer和Stevens[Reference 2]描述了这个架构的基础。EDSM架构中,每次每个连接 只由数据驱动一步(译注:例如,收一个包,动作一次),因此必须复用多个并发的连接(译注:必须复用一个进程处理多个连接),进程设计成状态机每次收到 一个时间就处理并变换到下一个状态。
在空闲状态时,EDSM调用select/poll/epoll等待网络事件,当一个特殊的连接可以读写时,EDSM调用响应的处理函数处理,然后处理下一个连接。EDSM架构 使用非阻塞的系统调用完成异步的网络IO。关于非阻塞的IO,请参考Stevens [Reference 3]。
为了利用硬件并行性能,可以创建多个独立的进程,这叫均衡的多进程EDSM,例如ZeusWeb服务器[Reference 4](译注:商业的高性能服务器)。为了更好的 利用多磁盘的IO性能,可以创建一些辅助进程,这叫非均衡的多进程EDSM,例如DruschelWeb服务器[Reference 5]。
EDSM架构可能是IAs的最佳架构,因为并发连接完全和内核进程解耦,这种架构有很高的负载能力,它仅仅需要少量的用户空间的资源来管理连接。
和MP架构一样,多核的EDSM架构也有很高的系统能力(多核性能,稳定性等),因为进程间没有资源共享,所以没有同步锁的负担。
不幸的是,EDSM架构实际上是基于线程的概念(译注:状态机保存的其实就是线程的栈,上次调用的位置,下次继续从这个状态开始执行,和线程是一样的), 所以新的EDSM系统需要从头开始实现状态机。实际上,EDSM架构用很复杂的方式模拟了多线程。
State Threads Library
StateThreads库结合了上面所有架构的优点,它的api提供了像线程一样的编程方式,允许一个并发在一个“线程”里面执行,但这些线程都在一个进程里面。 底层的实现和EDSM架构类似,每个并发连接的session在单独的内存空间。
译注:StateThreads提供的就是EDSM机制,只是将状态机换成了它的“线程”(协程或纤程),这些“线程”实际上是一个进程一个线程实现但表现起来像多线程。所以StateThread的模型是EDSM的高性能和高并发,然后提供了MT的可编程性和简单接口,简化了EDSM的状态机部分。
State Changes and Scheduling
每个并发的session包含它自己的栈环境(栈指针,PC,CPU寄存器)和它的栈。从概念上讲,一次线程上下文切换相当于进程改变它的状态。当然除了进程之外, 并没有使用线程(译注:它是单线程的方式模拟多线程)。和其他通用的线程库不一样,StateThreads库的设计目标很明确。线程上下文切换(进程状态改变) 只会在一些函数中才会发生(IO点,或者明确的同步点)。所以,进程级别的数据不需要锁来保护,因为是单线程。整个程序可以自由的使用静态变量和不可重入 的函数,极大的简化了编程和调试,从而增加了性能。这实际上是和协程(co-routine)类似,但是不需要显式的用yield指定——线程调用阻塞的IO函数被阻塞 而交出控制权是早晚的事。所有的线程(并发连接)都有同样的优先级,所以是非抢占式的调度,和EDSM架构类似。由于IAs是数据驱动(处理流程由网络缓冲区 大小和数据到达的次序决定),调度不是按时间切片的。
只有两类的外部事件可以被库的调度器处理,因为只有这类事件能被select/poll检测到:
-
IO事件:一个文件�描述符可读写时。
-
定时器时间:指定了timeout。
尽管这样,其他类型的事件(譬如发送给进程的信号)也能被转换成IO事件来处理。例如,信号处理函数收到信号时可以写入pipe,因此将信号转换成了IO事件。
为了能更好的发挥硬件并行的性能,和EDSM架构一样,可以创建均衡和非均衡的进程。进程管理不是库的功能,而是留给用户处理。
有一些通用的线程库,实现了多对一的模型(多个用户空间的线程,对一个内核执行对象),使用了和StateThreads库类似的技术(非阻塞IO,事件驱动的调度 器等)。譬如,GNU Portable Threads [Reference 6]。因为他们是通用库,所以它们和StateThreads有不同的目标。StateThreads不是通用的线程库, 而是为少数的需要获得高性能、高并发、高扩展性和可读性的IAs系统而设计的。
Scalability
StateThreads是非常轻量级的用户空间线程,因此创建和维护用户连接需要很少的资源。使用StateThreads的系统在高并发时能获得很高性能。
多CPU的系统上,程序需要创建多个进程才能利用硬件的平行能力。使用独立的进程是唯一获取高系统能力的方式,因为复制进程的资源是唯一的方式来避免锁和 同步这种负担的唯一方式。创建UNIX进程一般会复制进程的资源。再次强调,EDSM架构中,并发的连接和系统对象(进程线程)没有任何的联系,也就是说, StateThreads库将大量并发复用到了少量的独立的进程上,因此获得很高的系统能力和负载能力。
Performance
高性能是StateThreads库的主要目标之一,它实现了一系列的系统调用,尽可能的提高线程创建和切换的速度。例如,没有线程级别的信号屏蔽(和POSIX线程 不一样),所以线程切换时不需要保存��和恢复进程的信号屏蔽字,这样在线程切换时少了两个系统调用。信号事件能被高效的转换成IO事件(如上所述)。
Portability
StateThreads库使用了和EDSM架构同样的基础概念,包括非阻塞IO,文件描述符,IO复用。这些概念在大多数的UNIX平台都通用,所以UNIX下库的通用性 很好,只有少数几个平台相关的特性。
备注:SRS更新了State Threads支持了常见的现代CPU和OS,甚至包括aarch64和Windows,详细请看#22
State Threads and NSPR
StateThreads库是从Netscape Portable Runtime library (NSPR) [Reference 7]发展来的。NSPR主要的目标是提供一个平台无关的系统功能, 包括线程,线程同步和IO。性能和可扩展性不是NSPR主要考虑的问题。StateThreads解决了性能和可扩展性问题,但是比NSPR要小很多;它仅仅包含8个源文件, 却提供了在UNIX下写高效IAs系统的必要功能。
Conclusion
StateThreads是一个提供了编写IA的基础库,它包含以下优点:
- 能设计出高效的IA系统,包括很高的负载能力和系统能力。
- 简化了编程和调试,因为没有同步锁,可以使用静态变量和不可重入函数。
它主要的限制:
- 所有socket的IO必须要使用库的IO函数,因为调度器可以避免被阻塞(译注:用操作系统的socket的IO函数自然调度器就管不了了)。
References
- Apache Software Foundation, http://www.apache.org.
- Douglas E. Comer, David L. Stevens, Internetworking With TCP/IP, Vol. III: Client-Server Programming And Applications, Second Edition, Ch. 8, 12.
- W. Richard Stevens, UNIX Network Programming, Second Edition, Vol. 1, Ch. 15.
- Zeus Technology Limited, http://www.zeus.co.uk.
- Peter Druschel, Vivek S. Pai, Willy Zwaenepoel, Flash: An Efficient and Portable Web Server. In Proceedings of the USENIX 1999 Annual Technical Conference, Monterey, CA, June 1999.
- GNU Portable Threads, http://www.gnu.org/software/pth/.
- Netscape Portable Runtime, http://www.mozilla.org/docs/refList/refNSPR/.
Other resources covering various architectural issues in IAs
- Dan Kegel, The C10K problem, http://www.kegel.com/c10k.html.
- James C. Hu, Douglas C. Schmidt, Irfan Pyarali, JAWS: Understanding High Performance Web Systems, http://www.cs.wustl.edu/~jxh/research/research.html.
Example
The example bellow demonstrate how to use ST to start 30K coroutines, each is able to serve a network connection:
#include <stdio.h>
#include "st.h"
void* do_calc(void* arg){
int sleep_ms = (int)(long int)(char*)arg * 10;
for(;;){
printf("in sthread #%dms\n", sleep_ms);
st_usleep(sleep_ms * 1000);
}
return NULL;
}
int main(int argc, char** argv){
if(argc <= 1){
printf("Test the concurrence of state-threads!\n");
printf("Usage: %s <sthread_count>\n");
printf("eg. %s 10000\n", argv[0], argv[0]);
return -1;
}
if(st_init() < 0){
printf("st_init error!");
return -1;
}
int i;
int count = atoi(argv[1]);
for(i = 1; i <= count; i++){
if(st_thread_create(do_calc, (void*)i, 0, 0) == NULL){
printf("st_thread_create error!");
return -1;
}
}
st_thread_exit(NULL);
return 0;
}
First, please build State Threads on Linux as such:
mkdir -p ~/git && cd ~/git
git clone -b srs https://github.com/ossrs/state-threads.git
make linux-debug
Then, save the code as huge_threads.c and build:
gcc -I~/git/state-threads/obj -g huge_threads.c ~/git/state-threads/obj/libst.a -o huge_threads
Run the example:
./huge_threads 10000
10K report:
10000 threads, running on 1 CPU 512M machine,
CPU 6%, MEM 8.2% (~42M = 42991K = 4.3K/thread)
30K report:
30000 threads, running on 1CPU 512M machine,
CPU 3%, MEM 24.3% (4.3K/thread)
Another example is SRS, which is a simple, high efficiency and realtime video server, supports RTMP, WebRTC, HLS, HTTP-FLV, SRT, MPEG-DASH and GB28181.
